
Fundamentals of Reinforcement Learning - 03. Week 3. Value Functions & Bellman Equations
관련 자료 (RLbook2018 Pages 58-67)
- 용어설명
- 휴리스틱 : 정립된 공식이 아닌 정보가 온전하지 않은 상황에서의 노력, 시행착오, 경험 등을 통해서 지식을 알게 되는 과정.
- 주먹구구식의 규칙 (Rule of Thumb) 을 통해 지식을 습득하게 되는 과정
- 잘 추측하는 기술 (art of good guessing)
- 알고리즘과 달리 휴리스틱은 해결책의 발견을 보장하지 않는다.
- 그러나 휴리스틱은 알고리즘보다 효율적이다. (쓸모없는 대안책들을 실제 시도하지 않고도 배제 가능)
- 출처 : http://www.aistudy.com/heuristic/heuristic.htm
- 휴리스틱 서치
- 깊이우선 탐색이나 너비우선 탐색 등의 blind search method 는 goal 까지 의 경로를 찾는 상당히 소모적인 (exhaustive) 방법임.
- 즉 문제에 대한 해를 제공하지만 너무 많은 노드를 확장시키므로 실용적이지 못하다.
- 탐색작업을 축소시키기 위해 항상 옳은 해를 제공하지는 못하지만 대부분의 경우에 잘맞는 경험에 의한 규칙 (rules of thumb) 을 이용
- 이렇게 그래프로써 표현된 문제에 대한 특별한 정보를 이용하여 탐색 (Search) 작업을 빠르게 진행시키는 방식
- 출처 : http://www.aistudy.co.kr/heuristic/heuristic_search.htm
- 휴리스틱 : 정립된 공식이 아닌 정보가 온전하지 않은 상황에서의 노력, 시행착오, 경험 등을 통해서 지식을 알게 되는 과정.
-
Policies and Value Functions
- 거의 대부분의 강화학습 알고리즘은 가치함수 (value function) 을 추정하는 것을 포함한다.
- 상태 (States) 혹은 상태-액션 쌍(State-action pairs) 에 대한 함수
- 에이전트에게 주어진 상태 (혹은 주어진 상태에서 주어진 액션) 이 얼마나 좋은지 (how good) 추정하는 것
- 얼마나 좋은지 (how good) 란 기대되는 미래 보상값 혹은 기대되는 결과값에 대한 이야기임
- 미래의 보상 값은, 에이전트가 어떤 액션을 취할지에 달려있음
- 따라서 가치함수 (value function) 는 특정한 행동 방식 ( = Policy) 에 따라 정의된다.
- 일반적으로 정책 (Policy) 은 환경 (States) 에 따른 선택 가능한 행동 (Action) 을 선택하는 확률의 매핑 정보이다.
- $\pi ( a \mid s )$
- 에이전트가 정책(policy) $\pi$ 를 따른다 가정할 경우
- time t 시점에서 $S_t = s$ 일 때 $A_t = a$ 일 확률을 가리킨다.
- mdp 함수 $p$ 와 같이 $\pi$ 또한 평범한 함수이다.
- $\mid$ 는 각 $s \in S$ 에 대한 $a \in A(s)$ 의 확률 분포를 나타낸다.
- 강화 학습 함수는 에이전트의 경험 결과에 따라 어떻게 정책이 바뀔지를 지정한다.
- $\pi ( a \mid s )$
- $v_\pi (s)$ : policy $\pi$ 를 따를 때 state $s$ 일 때 가치 함수 (value function)
- $\pi$ 를 따를 때 $s$ 상태에서 시작할 경우 기대되는 결과값

- $E_\pi [\cdot]$ : 에이전트가 policy $\pi$ 를 따르고, $t$ 는 임의의 time step 일 때 에이전트가 제공하는 무작위 변수에 대한 기대 리턴값
- Terminal state 에 대한 위의 값은 0
- 우리는 $v_\pi$ 를 정책 $\pi$ 에 대한 state-value function 이라 한다.

- 위와 유사하게 policy $\pi$ 아래에서 state $s$ 에 action $a$ 를 취할 때의 value 를 측정할 경우 이를 $q_\pi (s,a)$ 로 정의할 수 있다.
- 이 때 $E_\pi [\cdot]$ 는 정책 $\pi$ 를 따를 경우 상태 $s$ 에서 시작하여 행동 $a$ 를 행했을 때 기대되는 리턴값을 뜻한다.
- 우리는 $q_\pi$ 를 정책 $\pi$ 에 대한 action-value function 이라 한다.
- 가치함수 $v_\pi$ 와 $q_\pi$ 는 경험을 통해 추정할 수 있다.
- 예를 들어 정책 $\pi$ 를 따르는 에이전트가 각각의 상태를 마주하고 이에 따른 리턴 값의 평균을 보관할 경우, 해당 상태에 직면하는 횟수가 무한에 가까워지면 평균 값은 상태의 가치, $v_\pi (s)$ 로 수렴한다.
- 마찬가지로 각 상태에 보관된 평균 값을 행동에 따라 분리한다면 이는 행동의 가치, $q_\pi (s,a)$ 로 수렴한다.
- 우리는 이러한 추정 방식을 Monte Carlo methods 라 한다. (많은 랜덤한 샘플의 실제 리턴값을 평균내는 것을 포함하고 있기 때문)
- 물론 이러한 방식은 상태값이 많으면 각 상태 별로 분리된 평균값을 각각 가지는 것에 어려움이 있다.
- 대신, 에이전트는 $v_\pi$ 와 $q_\pi$ 를 파라미터화된 함수로 유지하고 이 파라미터를 조정하는 방식을 사용한다.
- 이 또한 정확한 추정치를 구할 수 있다.
- 이 경우 파라미터화 된 function approximator (함수 근사) 에 달려있다. (이는 이후 과정에서 설명)
- 가치함수의 핵심요소들은 강화학습 이나 다이나믹 프로그래밍 전반에 걸쳐 사용되며, 재귀적인 표현법으로 표현될 수 있다.
- 다음 조건은 $s$ 값과 그 값의 가능한 후속 states 사이에서 일관성있게 유지된다.

- 위의 재귀식은 아래의 조건을 따른다.
- $a \in A(s)$
- $s’ \in S$ (Episodic problem 일 경우 $S^+$)
- $r \in R$
- 위 식은 실제로 모든 변수 $a, s’, r$ 에 대한 합계이다.
- 예상값을 구하기 위해 $\pi(a|s)p(s’,r|s,a)$ 확률을 계산하여 [ ] 안의 값에 가중치를 부여하고 이 모든 확률에 대한 합계를 구한다.
- 위의 3.14 방정식은 Bellman equation for $v_\pi$ 이다.
- 이것은 상태의 가치, 그리고 그 상태의 후속 상태의 가치에 대한 관계를 나타낸다.

- 에이전트는 state $s$ 에서 policy $\pi$ 에 기반한 행동들 ($a \in A(s)$) 을 할 수 있다.
- 환경은 함수 $p$ 에 따라 주어진 역학 (dynamic) 을 통해 보상 $r$ 과 함께 여러 다음 상태 중 하나인 $s’$ 로 응답할 수 있음.
- 벨만 방정식 (The Bellman equation (3.14.)) 은 모든 가능성에 대해 평균을 내며, 발생 확률에 따라 가중치를 부여함.
- 시작 상태의 값은 다음 상태의 (할인된) 값과 보상값의 합과 반드시 같다.
- 위의 다이어그램을 backup diagrams 라 한다.


- 위의 다이어그램은 $v_\pi (s)$ 와 $q_\pi (s)$ 의 관계를 나타낸다.
-
Example 3.5 : Gridworld
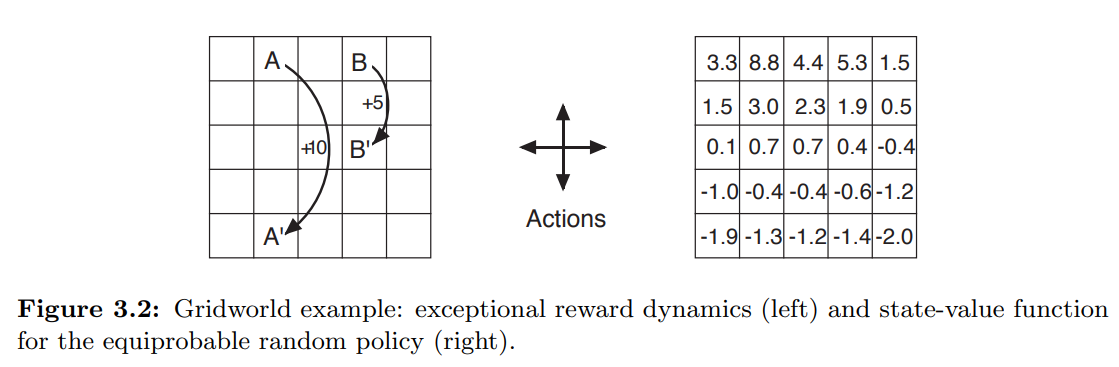
- 위 gridworld 는 단순한 유한 MDP 를 나타낸다.
- 그리드의 각 셀은 환경의 state 를 나타낸다.
- 각 셀에서 동,서,남,북 의 action 이 가능하며, 해당 방향의 셀로 이동하게 된다.
- 가장자리에서의 이동은 이동 없이 해당 셀에 머물게 되나 보상으로 -1 을 얻게 된다.
- 특별한 상태인 A, B 를 제외하고 다른 곳에서의 이동은 보상으로 0 을 얻는다.
- A 에서의 이동은 action 의 방향과 관계없이 A’ 로 이동하게 되며 +10의 보상을 얻는다.
- B 에서의 이동은 action 의 방향과 관계없이 B’ 로 이동하게 되며 +5의 보상을 얻는다.
- 모든 상태에서 동일한 확률로 랜덤한 action 을 취하는 정책을 취할 때 우측의 그림은 그에따른 가치함수 (discounted reward $\gamma=0.9$)를 나타낸다.
- 위 가치함수는 (3.14) 의 선형방정식 (linear equations) 을 푼 결과이다.
- 가장자리는 값 이 낮은데, 이는 가장자리에 부딪힐 확률이 높기 때문이다.
- State A 는 보상 값 +10 보다 낮은 가치를 가지는데 전이된 A’ 에서 감점될 확률이 높기 때문이다.
- B 는 B’ 로 전이되었을 때 A’ 보다 감점될 확률이 적다.
-
Example 3.6 : Golf

- 그림 중 위의 부분에 대한 설명임.
- 공을 홀에 넣을 때까지 각 스트로크에 대해 -1 의 페널티 (마이너스보상).
- 공의 위치가 상태이며, 상태 값은 홀로부터 상태 위치 까지의 스트로크 횟수 (음수) 값이다.
- 행동은 공을 조준, 스윙하는 방법과 어떤 클럽을 선택하는가 등이 있지만 전자는 주어진 것으로 받아들이고 후자의 선택에만 집중한다.
- 홀의 값은 0
- 그린의 어느 곳에서든 퍼팅을 할 수 있다고 가정하며, 이러한 상태의 값은 -1
- 그린 밖에서는 퍼팅으로 홀에 도달할 수 없으며, 퍼팅을 통해 그린에 도달할 수 있다면 -2
- 마찬가지로 -2 등고선으로 퍼팅이 가능한 모든 위치는 -3 값을 가지며, 위와 같은 방식으로 등고선이 그려짐
- 퍼팅으로 모래 함정에서 벗어날 수 없으므로 $-\infty$ 의 값을 가지게 됨
- 전반적으로 퍼팅으로 티에서 홀 까지 가는데 6타가 걸림.
- 거의 대부분의 강화학습 알고리즘은 가치함수 (value function) 을 추정하는 것을 포함한다.
-
Optimal Policies and Optimal Value Functions
- 강화학습 문제를 푼다는 것은, 간단히 말하면 긴 흐름 속에서 많은 보상을 획득하는 정책을 찾는 것이다.
- 유한 MDP 문제에서 우리는 Optimal policy 를 아래와 같이 정의할 수 있다.
- 가치함수는 전체 정책에서 부분적인 순서를 결정한다.
- 정책 $\pi$ 가 정책 $\pi’$ 와 비교하여 모든 상태에서 예상되는 리턴 값이 크거나 같을 경우 정책 $\pi$ 는 정책 $\pi’$ 보다 좋거나 동등하다고 본다.
- $\pi \ge \pi’$, if and only if $v_\pi (s) \ge v_\pi’ (s)$ for all $s \in S$.
- 항상 최소한 하나의, 타 정책보다 나은 정책이 있는데 이를 최적 정책 (optimal policy) 라 한다.
- 우리는 optimal policies 를 $\pi_*$ 로 표기한다.

- 이는 optimal state-value function $v_*$ (for all $s \in S$) 를 공유한다.

- 이는 또한 optimal action-value function $q_*$ (for all $s \in S$ and $a \in A(s)$) 를 공유한다.

- 위 두 함수의 정의에 따라 위와같이 표현할 수 있다.
-
Example 3.7 : Optimal Value Functions for Golf
- 그림 중 아래 부분에 대한 설명임. (optimal action-value function $q_*(s,driver)$)
- 드라이버로 먼저 스트로크를 한 다음 나중에 드라이버나 퍼터 중 더 나은 쪽을 선택하는 경우 각 상태의 값
- 드라이버를 사용하면 공을 더 멀리 칠 수 있지만 정확도는 떨어져, 홀에서 가까운 부분만 -1 이 됨.
- 스트로크가 두번 있는 경우 -2 등고선에서 볼 수 있듯 더 먼 곳에서 홀까지 도달할 수 있음.
- 즉, 그린에만 떨어지면 퍼터를 사용할 수 있음.
- Optimal action-value function 은 처음 특정 행동을 한 이후에 값을 제공 (위의 경우 우선 드라이버를 사용하고 그 뒤에 무엇을 사용할지를 결정)
- -3 등고선은 더 멀리 있으며 시작 티를 포함함. 티에서 가장 좋은 순서는 드라이버2개, 퍼트1개로 공을 홀에 넣는 것임.
- 벨만 최적 방정식
- $v_*$ 는 정책에 대한 가치함수이기 때문에 벨만 방정식(3.14) 에 의해 주어진 상태 값에 대한 자기 일관성 조건을 충족해야 한다.
- 하지만 최적 가치 함수이기 때문에 $v_*$ 의 일관성 조건은 특정 정책을 참조하지 않고 특별한 형태로 작성할 수 있음.
- 이것은 $v_*$ 에 대한 벨만 방정식 또는 벨만 최적 방정식 (Bellman Optimality equation) 이라 함.
-
직관적으로 Bellman 최적 방정식은 최적 정책 하의 상태 값이 해당 상태에서 최상의 조치에 대한 기대 수익과 같아야 한다는 사실을 나타냄.
-
마지막 두 방정식은 벨만 최적 방정식 ($v_*$) 의 두가지 형태를 나타낸다.
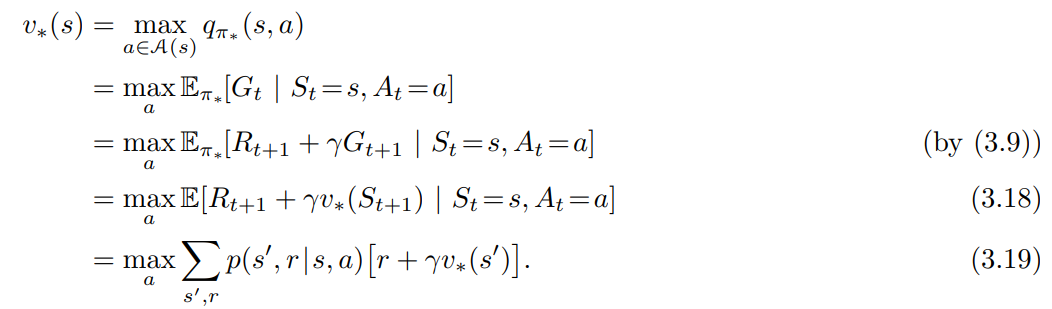
-
벨만 최적방정식 ($q_*$) 는 아래와 같이 표현할 수 있다.

-
아래는 벨만 최적방정식에 대한 backup diagrams 이다.

- 이는 $v_\pi$ 와 $q_\pi$ 의 backup diagrams 와 같으나, 호 (arc) 가 추가되었음.
- 에이전트 선택 지점에 호가 추가되어 타 정책에 의해 주어진 예상 값이 아닌 해당 선택에 대한 최대값이 취해짐을 나타냄.
-
왼쪽 backup diagram 은 3.19의 식이, 오른쪽은 3.20의 식이 표현된 것임.
- 유한 MDP 의 경우 $v_*$ (3.19) 에 대한 고유한 솔루션이 존재한다.
- 벨만 최적방정식은 각각의 state 별로 존재하는 방정식이다.
- 따라서 n개의 state 가 있을 경우 n 개의 방정식과 n 개의 미지수가 존재하게 된다.
- 만약 환경의 역학 $p$ 를 알면 비선형 방정식 시스템을 풀기 위한 다양한 방법 중 하나를 선택하여 $v_*$ 에 대한 방정식을 풀 수 있다.
- $v_*$ 를 알게 되면, 최적 정책을 결정하기가 상대적으로 쉽다.
- 모든 상태 s 에 대해 벨만 최적 방정식의 최대값을 얻는 하나 또는 그 이상의 action 이 존재하고, 이런 action 에만 0 이 아닌 확률을 배분하는 정책이 최적 정책이다.
- 즉 최적 가치 함수 $v_*$ 를 알면, one-step-ahead search 를 통해 어떤 action 이 최적의 action 인지 알게 된다.
- 다른 용어로 (optimal evaluation function $v_*$) 의 측면에서 greedy policy 라 할 수 있음.
- greedy 함은 지역적 혹은 즉각적 고려를 통한 결정이며, 보다 나은 미래의 대안 가능성을 고려하지 않음.
- $v_*$ 는 이미 미래 행동의 모든 가능성을 고려하고 반영한 결과값이므로, 긴 기간동안의 리턴값을 지역적, 즉각적인 수량으로 나타낸 값이 된다.
- $q_*$ 를 알면, 최적의 행동을 선택하기 더 쉬워진다.
- 에이전트는 one-step-ahead search 를 할 필요 없이 s 상태에서 $q_*(s,a)$ 를 최대화 할 행동 a 를 선택하면 된다.
- $q_*$ 는 장기적인 기대 리턴값을 각각의 state-action pair 에 제한한다.
- action-value function 은 더 효율적으로 모든 one-step-ahead search 의 결과값을 캐싱한다.
- 가능한 후속 상태 및 해당 값들에 대해 알 필요 없이 (즉, 환경의 역학에 대해 알 필요 없이) 최적 행동을 선택할 수 있다.
-
Example 3.8: Solving the Gridworld

- Example 3.5 의 Gridworld 문제에 대한 벨만 방정식 (Bellman equation for $v_\pi$) 를 풀었다고 가정
- 중간 이미지는 optimal value function $v_*$ 를 나타낸다.
- 우측 이미지는 그에 상응하는 최적 정책 (optimal policies) 이다.
-
Example 3.9: Bellman Optimality Equations for the Recycling Robot

- 3.19 의 수식을 이용, 벨만 최적 방정식을 Recycling robot example 에 적용할 수 있다.
- states : high, row / actions : search, wait, recharge 를 각각 h, l, s, w, re 로 축약한다.
- 상태가 2개이므로 벨만 최적 방정식은 2개의 방정식으로 구성된다.
- $v_* (h)$ 에 대한 방정식은 위와 같이 표기할 수 있다.
- $r_s, r_w, \alpha, \beta, \gamma$ ($0 \le \gamma < 1, 0 \le \alpha,\beta \le 1$) 의 어떠한 케이스를 선택해도 정확히 한 쌍의 숫자, $v_* (h), v_* (l)$ 이 남는다. 이는 동시에 두 비선형 방정식을 만족함을 보여준다.
- Bellman 최적 방정식의 한계
- Bellman 최적 방정식의 해결은 최적의 정책을 찾고, 강화 학습 문제를 해결할 수 있음을 보여줌.
- 그러나 이 솔루션은 실제로 유용하지 않음.
- 모든 가능성을 내다보고 예상되는 보상 측면에서 발생 가능성을 계산하는 검색과 유사함.
- 실제로 거의 적용되지 않는 최소한 세 가지 가정에 의존함
- 환경의 역학을 정확하게 알고 있음.
- 솔루션 계산을 완료하기에 충분한 계산 리소스가 있음
- Markov 속성
- 예를 들어 첫 번째와 세 번째 가정은 백개먼 게임에 아무런 문제가 없지만 두 번째 가정은 큰 장애물이 됨.
- 게임에는 약 $10^{20}$ 개의 상태가 있기 때문에
- 오늘날의 가장 빠른 컴퓨터에서 $v_*$ 에 대한 Bellman 방정식을 푸는 데 수천 년이 걸리며
- $q_*$ 를 찾는 것도 마찬가지이다.
- 강화 학습에서는 일반적으로 근사 솔루션 (approximate solutions) 으로 만족해야 함.
- Bellman 최적 방정식을 근사로 푸는 방법으로 다양한 의사 결정 방법이 있음.
- 예를 들어 휴리스틱 검색 방법은 (3.19) 의 오른쪽을 여러 번 확장하여 어느 정도 깊이까지 형성함
- 이를 통해 가능성에 대한 트리구조를 만들고, 휴리스틱 평가 함수를 사용하여 리프 노드에서 $v_*$ 를 근사함.
- $A^*$ 와 같은 휴리스틱 검색방법은 거의 항상 에피소드 사례를 기반으로 함.
- 동적 계획법 (dynamic programming) 이 Bellman 최적 방정식과 훨씬 더 밀접한 관계가 있음.
- 많은 강화 학습 방법은 transition 에 대한 지식 대신 transition 에 대한 경험을 토대로 근사치 해결을 함.
- Bellman 최적 방정식을 근사로 푸는 방법으로 다양한 의사 결정 방법이 있음.
- Optimality and Approximation
- 최적 가치 함수와 최적 정책에 대해 정의를 했고, 실제로 이를 학습한 에이전트는 수행을 잘 하였으나 이러한 경우는 매우 드물다.
- 이러한 종류의 작업은 엄청난 계산비용으로만 생성할 수 있다.
- 환경의 역학에 대해 완전하고 정확한 모델이 있더라도 벨만 최적 방정식을 풀어 최적의 정책을 계산하는 것은 일반적으로 불가능하다.
- 예를 들어 체스와 같은 보드게임도 여전히 최적의 수를 계산할 수 없음
- 에이전트가 직면하는 문제
- 단일 time-step 에서 수행할 수 있는 계산의 양
- 사용 가능한 메모리 양 (가치함수, 정책, 모델 근사치의 구축 등에 필요)
- 작고 유한한 상태집합이 있는 작업에서는 각 상태 혹은 상태-행동 쌍 에 대해 배열 또는 테이블을 사용하여 근사치를 형성할 수 있음
- 우리는 이런 경우를 tabular case, tabluar method (테이블 형식) 이라 하나 실질적인 문제들은 테이블 항목으로 표현할 수 없을 정도로 훨씬 더 많은 상태를 가지고 있음
- 이러한 경우 더 간결한 형태의 매개 변수화된 함수 표현을 사용하여 근사화 해야 함
- 근사화
- 강화학습의 온라인 특성
- 자주 경험하는 상태에 대해 좋은 결정을 내릴 수 있도록 더 많은 노력을 기울임
- 드물게 경험하는 상태는 상대적으로 더 적은 노력을 기울임
- 최선의 선택이 아닌 선택을 할 확률이 매우 낮은 보상에 미미한 영향을 주는 상태들
- 예를 들어 백개먼 게임에서 실제로 거의 일어나지 않는 상황에서 악수를 둘 수 있지만, 전문가와 뛰어난 기술로 플레이 할 수 있음
- 수 많은 다양한 환경에서 실제로 잘못된 결정을 내릴 확률이 있음.
- 이는 MDP 를 근사화 하여 해결하는 다른 접근방식과 강화학습을 구별하는 핵심 속성중 하나임
- 강화학습의 온라인 특성
- 최적 가치 함수와 최적 정책에 대해 정의를 했고, 실제로 이를 학습한 에이전트는 수행을 잘 하였으나 이러한 경우는 매우 드물다.
Policies and Value Functions
-
Specifying Policies
- 학습목표
- 정책 (Policy) 은 각 가능한 상태 (State)에 대한 행동 (Action) 의 분포임을 인지한다.
- 확률론적 정책 (Stochastic Policies) 과 결정론적 정책 (Deterministic Policies) 의 유사점과 차이점을 설명한다.
- 잘 정의된 정책의 특성을 식별한다.
- 주어진 MDP 에 유효한 정책의 예시
- Deterministic policy (결정론적 정책)
- 각 상태에 하나의 행동을 매핑
- $\pi(s) = a$
-
테이블로 표현 가능
State Action $s_0$ $a_1$ $s_1$ $a_0$ $s_2$ $a_0$ -
예시

- Stochastic policy (확률론적 정책)
- 각 상태에서 행동이 가지는 확률을 표현
- 하나의 상태에서도 각각 다른 행동이 선택될 수 있음 (확률이 0이 아닐 경우)
- $\pi(a|s)$
-
확률 그래프로 표현 가능

-
예시

- 정책은 오직 현재 상태에만 영향을 받는 것이 중요함.
- 시간이나 이전 상태와 같은 요소에 영향을 받지 않아야 함.
- 50% : 50% 의 행동 확률이라고 번갈아 가며 행동하지 않음 (이것은 현 상태 외의 영향을 받은 정책임.)
- 이런 면을 상태의 요구사항이며, 에이전트의 제한은 아닌 것으로 여기는 편이 좋음.
- 현재 상태에 현재 행동을 결정할 모든 요소가 포함되어 있어야 함.
- 시간이나 이전 상태와 같은 요소에 영향을 받지 않아야 함.
- MDP 에서는 상태가 결정을 위한 모든 정보를 포함한 것으로 가정한다.
- 만약 번갈아 가며 하는 행동이 높은 보상값을 제공한다면, 상태값에 마지막 행동값이 포함되어야 한다.
- 학습목표
-
Value Functions
-
학습목표
- 강화학습에서 상태가치함수 (state-value functions) 와 행동가치함수 (action-value functions) 의 역할에 대한 설명
- 가치 함수 (value function) 와 정책 (policy) 간의 관계 설명
- 주어진 MDP 에 대해 유효한 가치함수 생성
- 개념 설명
- 가치함수는 지연된 보상을 나타낸다.
- 강화학습에서는 장기적으로 최대의 보상을 얻는 정책을 학습하는 것을 목표로 한다.
-
State-value functions
- $G_t = \sum_{k=0}^\infty \gamma^k R_{t+k+1}$
- $v(s) \doteq E [G_t|S_t=s]$
- 주어진 환경에 대해 기대되는 보상 값을 의미
- 이 의미에 의해 value function 은 주어진 policy (agent 가 어떤 action을 취할 것인지) 에 영향을 받는다는 것을 의미
- $v_\pi (s) \doteq E_\pi [G_t|S_t=s]$
- 주어진 정책 하에 현 상태에 기대되는 리턴값
-
Action-value functions
- $q_\pi (s,a) \doteq E_\pi [G_t|S_t=s,A_t=a]$
- s에서 a를 선택한 후 정책을 따랐을 시 기대되는 리턴값
- Value function 의 의미
- 장기적인 결과를 관찰하기 위해 기다리는 대신
- 현재 상황의 품질을 질의할 수 있음
- 이 리턴 값은 즉시 사용할 수 없음
- 정책 및 환경 역학의 확률로 인해 리턴 값이 무작위일 수 있음
- Value function 은 미래의 모든 기대되는 리턴값을 평균값으로 요약함
- 이를 토대로 다른 정책들의 질을 판단할 수 있게 됨.
- Value function 의 예시 : Chess
- 체스는 episodic MDP 이다.
- State : 모든 말의 현 위치
- Action : 합법적인 이동
- Reward : 게임의 승리(+1), 패배 또는 무승부(0)
- 위의 보상으로 경기 중 에이전트가 얼마나 잘 플레이하는지에 대해 알 수 없음.
- 또한 보상을 보려면 에피소드가 끝날 때 까지 기다려야 함.
- 이 때 가치함수는 훨씬 더 많은 것을 알려줄 수 있음.
- 상태 가치함수 값은 단순히 현 Policy 를 따랐을 경우 이길 확률을 말함.
- 상대방의 움직임은 상태 전이이다.
- action value function 은 policy 를 따랐을 경우 현 동작을 통해 이길 확률을 나타낸다.
-
-
Rich Sutton and Andy Barto : A brief History of RL
Bellman Equations
-
Bellman Equation Derivation
- 학습목표
- 상태가치함수 (state-value function) 에 대한 Bellman 방정식 유도
- 행동가치함수 (action-value function) 에 대한 Bellman 방정식 유도
- Bellman 방정식이 현재와 미래 가치를 연관시키는 방법을 이해
- State-value Bellman equation
- $G_t = \sum_{k=0}^\infty \gamma^k R_{t+k+1}$
- $v_\pi (s) \doteq E_\pi [G_t|S_t=s]$
- $=E_\pi [R_{t+1} + \gamma G_{t+1}|S_t=s]$
- $=\sum_a \pi(a|s) \sum_{s’} \sum_r p(s’,r|s,a)[r+\gamma E_\pi [G_{t+1}|S_{t+1}=s’]]$
- $=\sum_a \pi(a|s) \sum_{s’} \sum_r p(s’,r|s,a)[r+\gamma v_\pi (s’)]$
- Action-value Bellman equation
- $q_\pi (s,a) \doteq E_\pi [G_t|S_t=s,A_t=a]$
- $=\sum_{s’} \sum_r p(s’,r|s,a)[r+\gamma E_\pi [G_{t+1}|S_{t+1}=s’]]$
- $=\sum_{s’} \sum_r p(s’,r|s,a)[r+\gamma \sum_{a’} \pi(a’|s’)E_\pi[G_{t+1}|S_{t+1}=s’,A_{t+1}=a’]]$
- $=\sum_{s’} \sum_r p(s’,r|s,a)[r+\gamma \sum_{a’} \pi(a’|s’)q_\pi (s’,a’)]$
- 현 state value 혹은 state/action value 는 미래의 state value 혹은 state/action value 표현법으로 재귀적 표현이 가능하다.
- 학습목표
-
Why Bellman Equations?
- 학습목표
- Bellman 방정식을 이용해 가치함수 (value functions) 를 계산
-
예제 : Gridworld
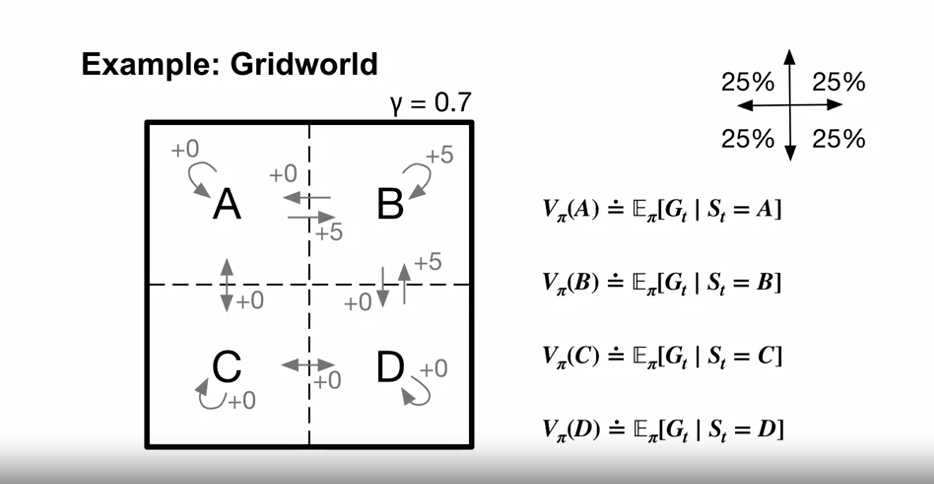



- 벨만 방정식은 가능한 모든 미래의 값을 무한히 더해가는 과정을 선형대수 문제로 치환시켜 준다.
- 벨만 방정식의 한계
- 체스게임과 같이 가능한 상태의 양이 많은 경우
- 위의 예시의 경우 상태가 4개이기 때문에 4개의 선형 방정식을 풀면 되지만..
- 체스 게임의 경우 $10^{45}$ 개의 선형 방정식을 풀어야 함.
- 학습목표
Optimality (Optimal Policies & Value Functions)
-
Optimal Policies
- 개요
- 정책 : 에이전트가 어떻게 행동할지를 나타내는 것
- 정책이 결정된 후 value function 을 찾아볼 수 있다.
- 강화학습의 목표는 특정 정책을 평가하는 것이 아닌 최적의 정책을 찾는 것이다.
- 학습목표
- Optimal policy 에 대한 정의
- 특정 정책이 어떻게 모든 상태에서 다른 모든 정책만큼 좋을 수 있는 것인지를 이해
- 주어진 MDP 에 대한 최적의 정책 식별
-
Optimal Policy 란?
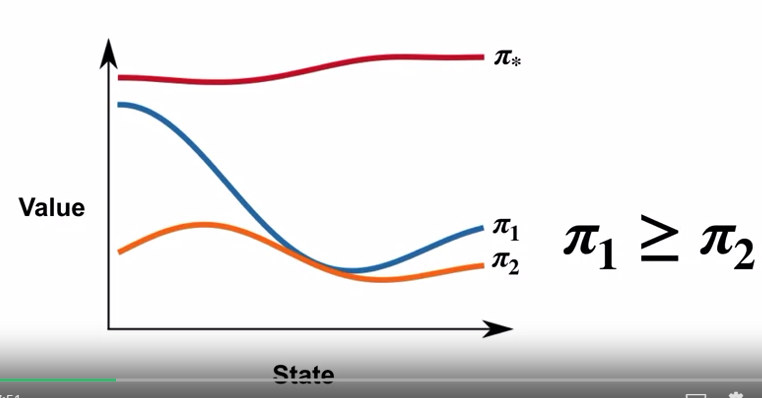
- 어떠한 상태에서도 타 정책과 같거나 더 좋은 경우
- 최소한 하나 이상의 Optimal Policy 가 존재
- 특정 상황에 $\pi_2$ 가 $\pi_1$ 보다 결과가 좋을 경우
- 해당 상황에서는 $\pi_2$ 정책을 사용하고 그 외의 경우 $\pi_1$ 을 사용하는 정책 $\pi_3$ 를 사용
- 작은 MDP 의 경우 직접적으로 풀 수 있지만…
- 2개의 결정론적 정책이 있을 경우 Brute-Force Search 로 문제 해결
- 하지만 일반적인 MDP 의 경우 $|A|^{|S|}$ 개의 결정론적 정책이 존재하여 Brute-Force Search 로 문제 해결이 불가함.
- 위의 경우 Bellman Optimality Equations 로 문제에 접근해야 함.
- 개요
-
Optimal Value Functions
- 학습목표
- 상태가치함수 (state-value functions) 에 대한 Bellman 최적 방정식 유도
- 행동가치함수 (action-value functions) 에 대한 Bellman 최적 방정식 유도
- Bellman 최적 방정식이 이전에 소개된 Bellman 방정식과 어떻게 관련되는지 이해
- Optimal Value Functions
- $v_*$ : $v_{\pi_*} (s) \doteq E_{\pi_*} [G_t|S_t=s] = \underset{\pi}{\max} v_\pi (s)$ for all $s \in S$
- $v_* (s) = \sum_a \pi_* (a|s) \sum_{s’} \sum_r p(s’,r|s,a)[r+\gamma v_*(s’)]$
- $v_* (s) = \underset{a}{\max} \sum_{s’} \sum_r p(s’,r|s,a)[r+\gamma v_*(s’)]$
- 언제나 하나 이상의 결정론적인 최적 정책이 존재한다.
- 모든 상태에서 하나의 최적 행동을 선택한다.
- 즉, 가장 높은 리턴값을 가지는 하나의 행동의 확률이 1이고, 나머지 행동의 확률은 0이 된다.
- Bellman Optimality Equation for $v_*$
- $q_*$ : $q_{\pi_*} (s,a) = \underset{\pi}{\max} q_\pi (s,a)$ for all $s \in S$ and $a \in A$
- $q_* (s,a) = \sum_{s’} \sum_r p(s’,r|s,a) [r+ \gamma \sum_{a’} \pi_{*} (a’|s’) q_* (s’,a’)]$
- $q_* (s,a) = \sum_{s’} \sum_r p(s’,r|s,a) [r+ \gamma \underset{a’}{\max} q_{*} (s’,a’)]$
- Bellman Optimality Equation for $q_*$

- 위의 벨만 최적 방정식으로는 $v_{*}$ 를 풀어낼 수가 없는데, $\max$ 함수가 선형이 아니기 때문이다.
- $\pi_{*}$ 값을 이용해 같은 방식으로 $v_{*}$ 를 구할 수도 없는데, $\pi_{*}$ 값을 모를 뿐더러, $\pi_{*}$ 를 구하는 것 자체가 목적이기 때문이다.
- 학습목표
-
Using Optimal Value Functions to Get Optimal Policies
- 학습목표
- 최적가치함수 (Optimal value function) 과 최적정책 (Optimal Policy) 의 연관성 이해
- 주어진 MDP 에 대한 최적가치함수 (Optimal value function) 확인
- Optimal Policy 와 Optimal Value Function 의 관계

- $p$ 와 $v_*$ 에 접근할 수 있다고 가정
- 한 단계 진행 시의 값을 구할 수 있을 경우, $A_2$ 가 최대의 값을 가짐을 알 수 있다.
- $\max$ 는 최대의 값을, $\arg\max$ 는 박스가 최대의 값을 가지게 하는 $a$ 값 자체를 나타낸다.

- $p$ 와 $v_*$ 에 접근할 수 있을 때 계산법

- $p$ 는 확률적 요소여서 알기 힘들지만, 충분히 많이 접근하면 위의 수식에 따라 최적 정책을 구할 수 있게 된다.
- $q_*$ 를 알 경우 최적 정책을 구하기 훨씬 쉬워지는데, 다음 스텝의 계산을 할 필요가 없기 때문이다.
- 학습목표
-
Week 3 Summary
-
Chapter Summary (RLbook2018 Pages 68-69)
- Reinforcement learning : Learning from interaction how to behave in order to achieve a goal.
- interaction : 에이전트와 환경이 이산 스텝의 시퀀스에 따라 상호작용하는 것
- actions : 에이전트에 의해 이루어지는 선택
- states : 선택에 영향을 주는 요소
- rewards : 선택을 평가하는 요소
- 모든 agent 내의 요소들은 완전히 알고 있고, 에이전트에 의해 컨트롤된다.
- 모든 agent 밖의 요소는 불완전하게 제어되며, 완전히 알고 있는 것일수도, 그렇지 않은 것일수도 있다.
- policy : 에이전트가 상태값을 인자로 한 함수를 통해 행동을 선택하는 확률적 규칙
- agent 의 목적 : 전체 시간 동안 받을 수 있는 보상을 최대화 하는 것
- Markov Decision Process (MDP)
- 위의 강화학습 설정이, 잘 정의된 전환 확률로 공식화되면 Markov Decision Process (MDP) 로 정의됨
- 유한 MDP : 유한한 상태, 행동 및 보상 세트가 있는 MDP
- 강화학습 이론의 대부분은 유한 MDP 로 제한하지만, 방법과 아이디어는 더 일반적으로 적용됨.
- return : 미래의 보상에 대한 함수로 agent 가 최대화 하려는 기대값
- 작업의 특성과 지연된 보상의 할인 정도에 따라 다른 정의를 가질 수 있음
- 할인이 적용되지 않은 return 식은 episodic tasks 에 맞는 방식
- episodic tasks : 상호작용이 에피소드에 따라 자연스럽게 중지되는 형태
- 할인이 적용된 return 식은 continuing tasks 에 맞는 방식
- continuing tasks : 상호작용이 자연스럽게 중단되지 않고 제한 없이 계속 이어지는 형태
- value functions and optimal value functions
- 정책의 가치함수는 에이전트가 해당 정책을 사용하는 경우, 각 상태 혹은 상태-행동 쌍과 그에 예상되는 수익을 할당함
- 최적 정책의 가치함수는 각 상태 혹은 상태-행동 쌍에 모든 정책 중 달성할 수 있는 최대의 기대 수익을 할당함
- 최적 가치함수를 사용하는 정책을 최적 정책이라 한다.
- 최적 정책은 하나이거나 하나 이상일 수 있다. (예: 50 : 50 의 확률론적 최적 정책)
- 최적 가치 함수와 관련하여 탐욕적인 모든 정책은 최적 정책임.
- Bellman optimality equations
- 최적 가치 함수을 만족하는 특별한 일관성 조건
- 이론적으로 최적 가치 함수를 풀 수 있는 방정식
- 최적 정책을 상대적으로 쉽게 결정할 수 있음
- 강화학습은 주어진 조건에 따라 다양한 방식으로 제기될 수 있음
- 에이전트의 지식
- 환경의 역학 (역학 함수 $p$ 의 4개의 인자) 을 아는 경우와 모르는 경우
- 계산 퍼포먼스 및 메모리 이슈
- 테이블 방식의 접근을 할지, 근사함수를 사용할 지에 대한 사항
- 에이전트의 지식
- 강화학습 문제는 최적 솔루션을 찾는 것 보다, 어떻게 근사해야 할지에 더 집중하는 것이 바람직하다.
- Reinforcement learning : Learning from interaction how to behave in order to achieve a goal.
댓글남기기